Published & Forthcoming Papers
Local Information Matters: A Rethink of Crowd Counting
Tianhang Pan and Xiuyi Jia*
European Conference on Artificial Intelligence (CCF B), 2025, Forthcoming.
The motivation of this paper originates from rethinking an essential characteristic of crowd counting: individuals (heads of humans) in the crowd counting task typically occupy a very small portion of the image. This characteristic has never been the focus of existing works: they typically use the same backbone as other visual tasks and pursue a large receptive field. This drives us to propose a new model design principle of crowd counting: emphasizing local modeling capability of the model. We follow the principle and design a crowd counting model named Local Information Matters Model (LIMM). The main innovation lies in two strategies: a window partitioning design that applies grid windows to the model input, and a window-wise contrastive learning design to enhance the model's ability to distinguish between local density levels. Moreover, a global attention module is applied to the end of the model to handle the occasionally occurring large-sized individuals. Extensive experiments on multiple public datasets illustrate that the proposed model shows a significant improvement in local modeling capability (8.7\% in MAE on the JHU-Crowd++ high-density subset for example), without compromising its ability to count large-sized ones, which achieves state-of-the-art performance.
Forthcoming.

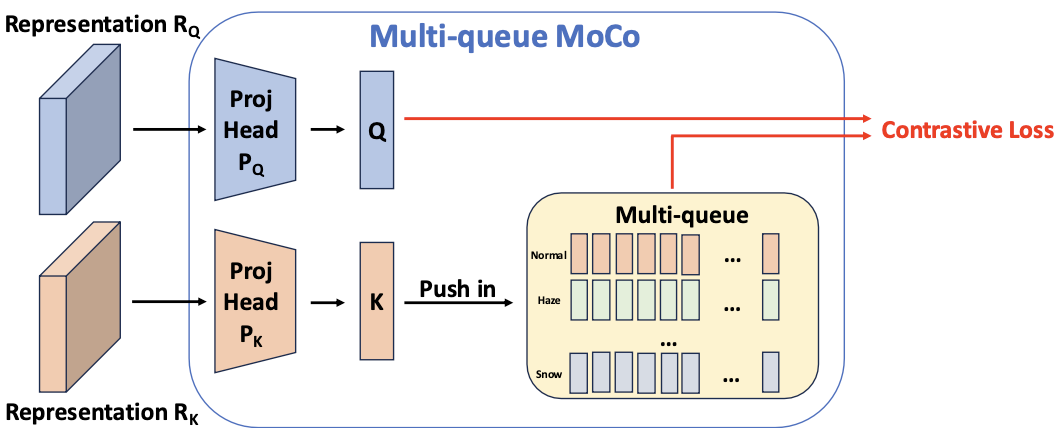
Boosting Adverse Weather Crowd Counting via Multi-queue Contrastive Learning
Tianhang Pan and Xiuyi Jia*
European Conference on Artificial Intelligence (CCF B), 2025, Forthcoming.
Currently, most crowd counting methods have outstanding performance under normal weather conditions. However, our experimental validation reveals two key obstacles limiting the accuracy improvement of crowd counting models: 1) the domain gap between the adverse weather and the normal weather images; 2) the weather class imbalance in the training set. To address the problems, we propose a two-stage crowd counting method named Multi-queue Contrastive Learning (MQCL). Specifically, in the first stage, our target is to equip the backbone network with weather-awareness capabilities. In this process, a contrastive learning method named multi-queue MoCo designed by us is employed to enable representation learning under weather class imbalance. After the first stage is completed, the backbone model is "mature" enough to extract weather-related representations. On this basis, we proceed to the second stage, in which we propose to refine the representations under the guidance of contrastive learning, enabling the conversion of the weather-aware representations to the normal weather domain. Through such representation and conversion, the model achieves robust counting performance under both normal and adverse weather conditions. Extensive experimental results show that, compared to the baseline, MQCL reduces the counting error under adverse weather conditions by 22%, while introducing only about 13% increase in computational burden, which achieves state-of-the-art performance.
GitHub Repo: MQCL
@misc{pan2025boosting,
title={Boosting Adverse Weather Crowd Counting via Multi-queue Contrastive Learning},
author={Tianhang Pan and Xiuyi Jia},
year={2025},
eprint={2408.05956},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.05956},
}
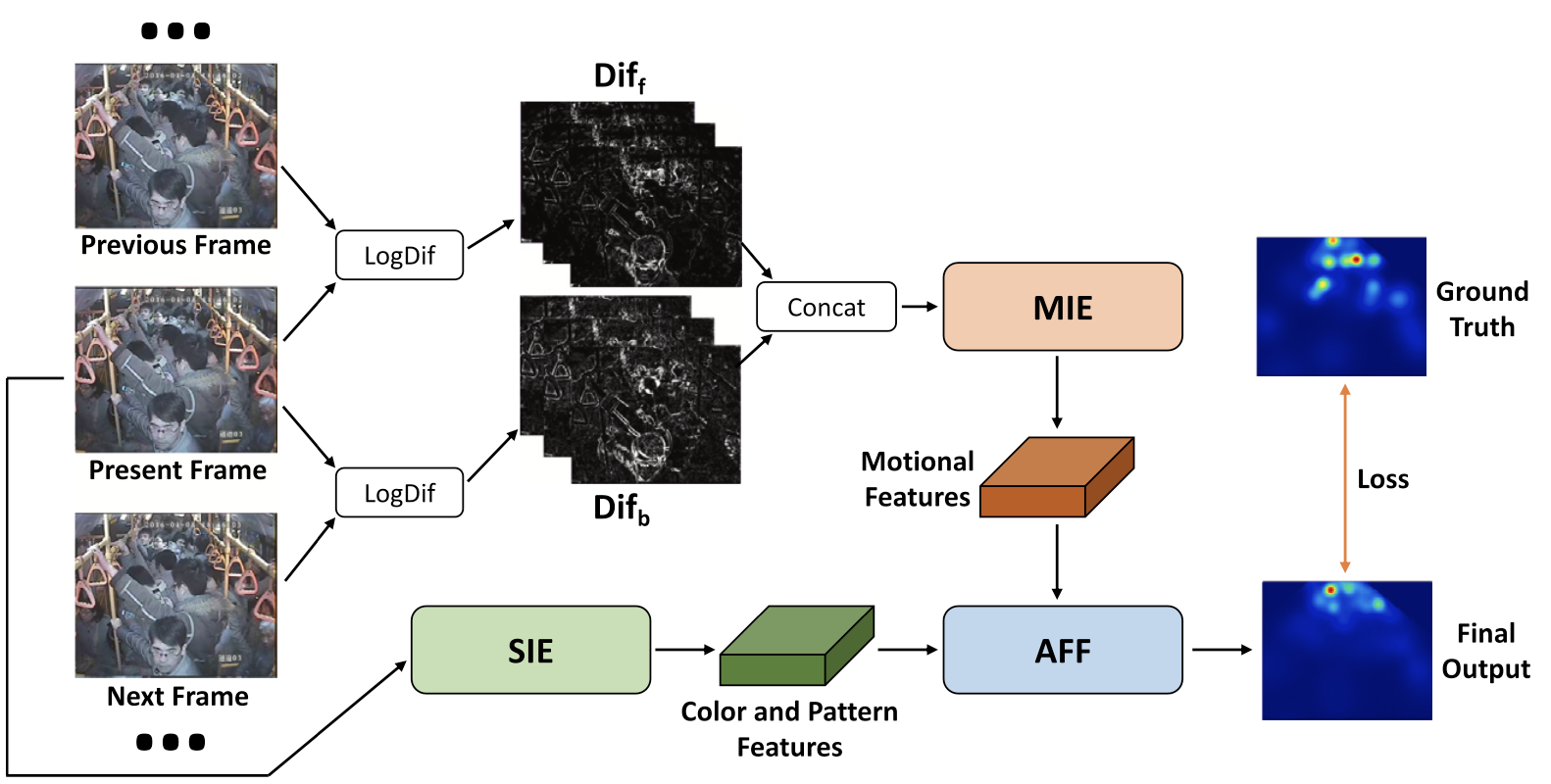
Motional Foreground Attention-based Video Crowd Counting
Miaogen Ling*, Tianhang Pan, Yi Ren, Ke Wang and Xin Geng
Pattern Recognition (CCF B), 2023, Volume 144, 109891.
In this paper, we tackle the problem of video crowd counting. Compared with single image crowd counting, video provides gradual spatial and temporal variation information that would help to strengthen the robustness of crowd counting. Therefore, it is critical to make full use of neighboring frames both in feature extraction and final prediction for current frame’s estimation. Based on the above observations, we propose a motional foreground attention-based video crowd counting method. Specifically, we first leverage an foreground estimation module based on ConvNeXt to extract the motional features from bidirectional frame differences and output a foreground estimation map. Then the motional features combined with the static features of current frame are sent into feature fusion network, where foreground estimation map is transformed as attention weights for crowd number estimation. Three new indoor video datasets are manually annotated. The proposed method achieves state-of-the-art performance on all indoor and outdoor video datasets.
GitHub Repo: MFA
@article{ling2025motional,
title = {Motional foreground attention-based video crowd counting},
journal = {Pattern Recognition},
volume = {144},
pages = {109891},
year = {2023},
issn = {0031-3203},
doi = {https://doi.org/10.1016/j.patcog.2023.109891},
url = {https://www.sciencedirect.com/science/article/pii/S0031320323005897},
author = {Miaogen Ling and Tianhang Pan and Yi Ren and Ke Wang and Xin Geng},
keywords = {Video crowd counting, Frame difference, Attention mechanism},
}